AI-narrated audio edition: Listen in 17 minutes
Generative AI in healthcare needs a robust context layer to operate safely and effectively. Discover how you can use our powerful accelerator to build your expert clinical context layer, augmenting large language model (LLM) outputs.
We'll explore how you can rapidly deploy a clinical copilot leveraging various context-building techniques. These include enhanced system messaging, document analysis using long context windows, vector search that overlays LLMs with your domain expertise, and agentic modelling with function calling.

"Large language models: a new chapter in digital health," proclaims a recent editorial in The Lancet Digital Health (vol 6, 2024), heralding the transformative potential of artificial intelligence in healthcare. As we stand on the cusp of this new era, integrating large language models (LLMs) into medical practice promises to revolutionise everything from patient education to clinical decision-making.
However, this path forward is not without its challenges.
While LLMs have demonstrated remarkable capabilities in medical question-answering, knowledge retrieval, and administrative task automation, they also present significant risks. Concerns about biases, inaccuracies, and the potential for "hallucinations" or confabulations underscore the need for a robust framework to guide their implementation in healthcare settings.
This is where the concept of a clinical copilot with experts in the loop comes in. This approach seeks to harness the power of generative AI while maintaining the critical oversight of human expertise. By building a comprehensive context layer that augments LLM outputs, we can create a system that combines the efficiency and vast knowledge base of AI with the nuanced understanding and ethical considerations of healthcare professionals.
The synergy between human insight and advanced AI capabilities is the cornerstone of an efficient and reliable clinical copilot. Let's explore how you can use our powerful generative AI accelerator platform to build your clinical copilot with a robust context layer.
Hallucinations are Bad Search Results From a Lack of Adequate Context
Imagine asking an LLM "What does your BMI tell you?". You might expect a straightforward answer, but the process behind the response is far more nuanced. LLMs don't operate with simple lookup tables. Instead, they convert your question into a "vector" – a mathematical representation of its meaning. This vector is then compared against a vast database of knowledge, also converted into vectors, to find the closest match. This "vector search" forms the basis of an LLM's response.
The challenge is that the database the LLM is searching is a 'compressed database'. As eloquently described in a recent New Yorker article, large language models can be thought of as "compression algorithms for human knowledge" (Chiang, 2023). They distil vast amounts of text into more compact representations, much like how a jpeg compresses an image. Just as a compressed image might lose some detail, an LLM's compressed knowledge can sometimes lead to inaccuracies or "hallucinations".
These hallucinations aren't random fabrications. Rather they are the result of the model attempting to construct a plausible response based on its compressed understanding. It's akin to trying to reconstruct a high-resolution image from a low-resolution version – the broad strokes might be correct, but the details can be off.
If the LLM hasn't encountered the concept of Body Mass Index (BMI) in its training data, it won't have a precise vector match. Instead, it attempts to interpolate an answer based on semantically similar concepts within its compressed database.
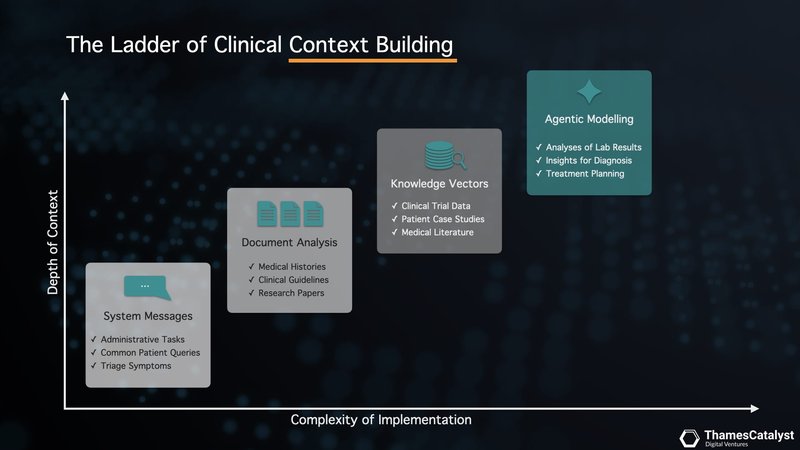
A Robust Context Layer for More Accurate Search
We can enhance the outcome of LLM queries by providing more context.
By providing additional, relevant information – a robust "context layer" – we can guide the LLM's search process more accurately. It's like giving the model a more detailed map to navigate its compressed database. In clinical settings, where precision is paramount, this context layer becomes crucial.
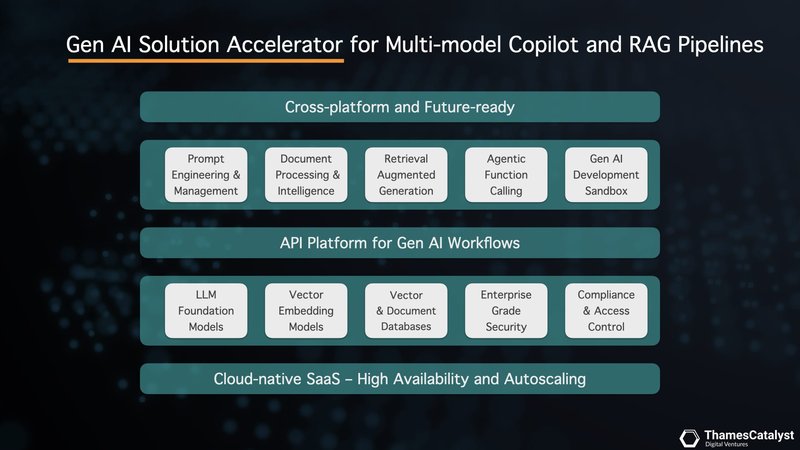
This is where our accelerator platform comes into play. Our platform is designed to build a robust context layer for your clinical copilot, augmenting the outputs of LLMs. It has built-in context-building techniques to improve query performance and safety. These include enhanced system messaging, document analysis using long context windows, vector search that overlays the LLM with your domain expertise, and agentic modelling with function calling.
These methods vary in their use cases, depth of contexts, and complexity of implementation, so let's unpack them one by one.
Enhanced System Messaging for Better Clinical Outcomes
One of the most direct and surprisingly powerful methods is through carefully crafted system messages, also known as prompt engineering. This technique allows us to embed deeper clinical understanding directly into the AI's decision-making process.
But why is prompt engineering so impactful? Remember the analogy of providing the LLM with a more detailed map to navigate its vast database? Prompt engineering takes this a step further by giving the AI a specialised lens through which to interpret the information on that map. This fine-tuning ensures that the AI prioritises domain-specific knowledge, leading to more clinically relevant and accurate outputs.
The potential of this approach was highlighted in a recent study published in npj Digital Medicine (Savage et al., 2024). Researchers at Stanford University demonstrated that by crafting "diagnostic reasoning prompts", LLMs could be guided to mimic the clinical reasoning processes of experienced physicians. This was particularly evident when the models were presented with challenging, free-response questions from the USMLE and NEJM case reports.
Intriguingly, the study also revealed that well-designed prompts could provide valuable insights into the reliability of the LLM's responses. By analysing the logical flow and factual basis of the model's reasoning, clinicians could gain a better understanding of when to trust – or perhaps question – the AI’s output. This transparency represents a crucial step towards overcoming the "black box" limitations often associated with AI in healthcare.
Our accelerator platform empowers you to harness the full potential of prompt engineering, and not just with a single LLM. Our multi-model platform seamlessly integrates with leading providers like OpenAI, Anthropic, Google Vertex, and Mistral AI, giving you the flexibility to experiment and deploy across a range of cutting-edge AI engines – all with instant switching capabilities.
But what if we could provide the AI with even greater context, allowing it to process and synthesise information from entire patient records or research articles? This is where the power of long context analysis comes into play.
Unlocking Deeper Insights: Document Analysis Using Long Context Windows
The landscape of LLMs is rapidly evolving, with one of the most significant advancements being the expansion of context windows. This capability is revolutionising document analysis in clinical settings, offering unprecedented depth and breadth of information processing.
Our accelerator platform harnesses this power, allowing you to upload and analyse documents exceeding 150 pages. This is a game-changer for analysing entire patient records, research articles, or clinical guidelines – all within a single analytical process.
In clinical practice, the ability to process extensive documents is invaluable. Consider a complex patient case with years of medical history spread across multiple reports. Traditional methods might require hours of manual review, but with long context windows, an AI can rapidly synthesise this information, identifying patterns and potential correlations that might otherwise be overlooked.
Similarly, when analysing clinical guidelines or research papers, the AI can maintain a holistic view of the document, ensuring that insights are contextualised within the broader framework of the text.
Our accelerator's multi-model approach is particularly advantageous here. Different LLM providers offer varying context window sizes, from a few thousand tokens to over 200,000. This diversity allows you to match the model to your specific needs, balancing depth of analysis with computational efficiency. For instance, you might use a model with a smaller context window for quick, targeted queries, while leveraging a larger window for comprehensive literature reviews or complex case analyses.
However, it's crucial to note that bigger isn't always better. While expanded context windows can provide deeper insights, they also come with increased computational costs and potential inefficiencies. The key is to strike a balance, using long context windows judiciously where they add the most value.
As we push the boundaries of what's possible with document analysis, we're also developing strategies to optimise this process. In the next section, we'll explore how vector search techniques can complement long context analysis, allowing for more targeted and efficient information retrieval from large document corpora.
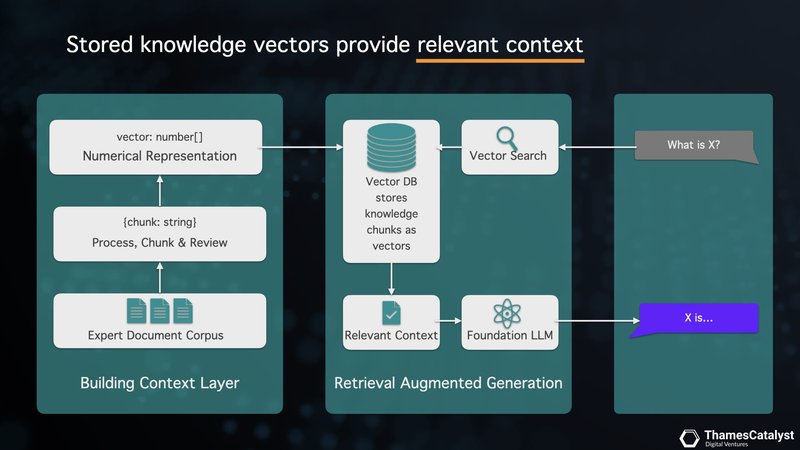
Clinical RAG – Overlaying Foundational LLMs with Domain Knowledge
Retrieval Augmented Generation (RAG) represents a significant leap forward in clinical AI applications. It addresses the limitations of LLMs by seamlessly integrating domain-specific knowledge. Our accelerator platform leverages RAG to create a powerful, context-aware clinical copilot.
Here's how it works: Your clinical document corpus – comprising expert documents, guidelines, and patient records – is processed through our accelerator. This content is segmented into manageable knowledge chunks, which are then transformed into knowledge vectors using an embedding model. These vectors are stored in a vector database, forming a rich, searchable knowledge base unique to your clinical domain.
The groundbreaking RECTIFIER study, recently published in the New England Journal of Medicine AI (Unlu et al., 2024), showcases the power of RAG in a real-world setting. RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review) combined RAG architecture with GPT-4 to automate clinical trial screening. This is a task that often involves analysing extensive patient records to determine eligibility.
Imagine needing to determine if a patient with a complex medical history qualifies for a clinical trial requiring them to have "symptomatic heart failure." Instead of relying on simple keyword matching, which might misinterpret incidental mentions of heart conditions, RECTIFIER, powered by RAG, employs a more nuanced approach. It analyses the query and performs a targeted search within a knowledge base built from clinical notes, identifying vectors containing relevant information about heart failure symptoms, diagnostic criteria, and related conditions. This enriched context is delivered to the LLM, enabling it to make a more accurate and nuanced assessment of the patient's eligibility.
Through this method, RECTIFIER achieved accuracy rates ranging from 97.9% to 100% across 13 target criteria, often exceeding the performance of trained human reviewers. Notably, RECTIFIER demonstrated superior accuracy in identifying symptomatic heart failure - 97.9% vs. 91.7% for human reviewers.
Beyond its accuracy, RECTIFIER demonstrated the striking cost-effectiveness of RAG, particularly when compared to using GPT-4 without RAG. The study reported a drastic reduction in inferencing costs from $15.88 to as low as 11 cents per patient.
This significant cost saving is primarily due to RAG's ability to provide only the relevant contexts, substantially reducing the context length the LLM needs to process. This targeted approach not only improves accuracy but also drastically reduces computational requirements and associated inferencing costs. By adopting our accelerator platform with RAG capabilities, you can unlock similar benefits in your clinical practice.
Sandbox for Agentic Modelling with Function Calling
We've seen how RAG empowers large language models with comprehensive clinical knowledge. Now, imagine taking it a step further, moving beyond simple question-answering to a world where AI agents can perform specific tasks within your clinical workflow. This is where agentic modelling with function calling comes in.
Picture this: an AI agent that not only understands a patient's complex medical history but can also automatically recommend additional lab tests based on identified risk factors. It could even suggest potential treatment adjustments aligned with the latest research. No longer just answering your questions, but proactively assisting with patient care – that's the potential unlocked by function calling.
Our accelerator platform provides a safe and controlled space, a sandbox, for clinicians and developers to explore this exciting frontier. Within this sandbox, you can define specific functions tailored to your needs. You can instruct your AI agent on how to analyse lab results, extract key insights from unstructured clinical notes, or even assist with generating personalised treatment recommendations.
However, the development of such AI agents for clinical decision support requires careful navigation of legal and regulatory frameworks. The EU AI Act, FDA guidelines, and existing medical device regulations all play crucial roles in shaping the development process.
This sandbox approach aligns well with the concept of "AI regulatory sandboxes" introduced in the EU AI Act (Gilbert, 2024). It provides a controlled, simulated environment where developers and clinicians can explore agentic modelling with function calling without immediately facing the full weight of regulatory scrutiny. This allows for rapid iteration and innovation while still maintaining a focus on safety and compliance.
The sandbox environment also facilitates the implementation of key regulatory requirements. Transparency and explainability can be built into the agents from the ground up, with mechanisms to provide clear rationales for recommendations. Human oversight can be integrated and tested, ensuring that the AI remains a supportive tool rather than a replacement for clinical judgment.
Moreover, the sandbox allows for rigorous testing of data quality and risk assessment processes. Developers can simulate various scenarios to identify potential risks to patient safety and fundamental rights, addressing these issues before the AI agent is considered for real-world application.
A New Chapter in Digital Health: Embracing the Promise, Addressing the Challenges
The emergence of generative AI marks a pivotal moment in the evolution of digital health. As we've explored, building robust context layers through techniques like enhanced system messaging, long-context document analysis, vector search, and agentic modelling is crucial to harnessing the power of LLMs safely and effectively.
This approach paves the way for clinical copilots that blend the strengths of AI – efficiency, scalability, and vast knowledge bases – with the irreplaceable expertise and ethical judgement of healthcare professionals.
The potential benefits are immense. With an ageing global population and increasingly burdened healthcare systems, generative AI offers a path towards personalised, accessible healthcare for everyone. However, realising this vision demands careful navigation of the rapidly evolving AI landscape, particularly when it comes to patient safety and regulatory compliance.
Collaboration is key. By fostering partnerships between AI developers and clinical experts within dedicated spaces like our generative AI lab, we can accelerate the translation of groundbreaking AI solutions into real-world clinical settings. Together, we can ensure a future where AI empowers healthcare professionals to deliver the best possible care, ushering in a new chapter of digital health defined by improved patient outcomes and a more sustainable healthcare ecosystem.
Are you ready to explore how generative AI can revolutionise your healthcare practice?
Don't just imagine the future of healthcare – build it. Reach out to us today and let's explore the possibilities together.
Start a conversationReferences:
- The Lancet Digital Health. Large language models: a new chapter in digital health. Lancet Digit Health. 2024;6(1):E1. doi:10.1016/S2589-7500(23)00254-6.
- Chiang, T. (2023, February 9). ChatGPT Is a Blurry JPEG of the Web. The New Yorker. https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web [Accessed 2 July 2024]
- Savage T, Nayak A, Gallo R, et al. Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine. npj Digit Med. 2024;7:20. doi:10.1038/s41746-024-01010-1.
- Unlu O, Shin J, Mailly CJ, et al. Retrieval-Augmented Generation–Enabled GPT-4 for Clinical Trial Screening. NEJM AI. 2024;1(7). doi:10.1056/AIoa2400181.
- Gilbert S. The EU passes the AI Act and its implications for digital medicine are unclear. npj Digit Med. 2024;7:135. doi:10.1038/s41746-024-01116-6.